ケーススタディ
ここでは、何らかの原因でユーザーからレスポンスが遅いという連絡があった場合を想定し、基本的な考え方を見ていきます。
状況確認
レスポンスが遅いなど、サーバーに障害が発生している際にまずチェックするのがtopコマンドの出力結果です。 topコマンドはサーバの稼働状況をリアルタイムに確認することができるコマンドで、コマンド一つで大量の情報を取得することができます。まずは画面の見方を確認していきましょう。
topコマンドの見方
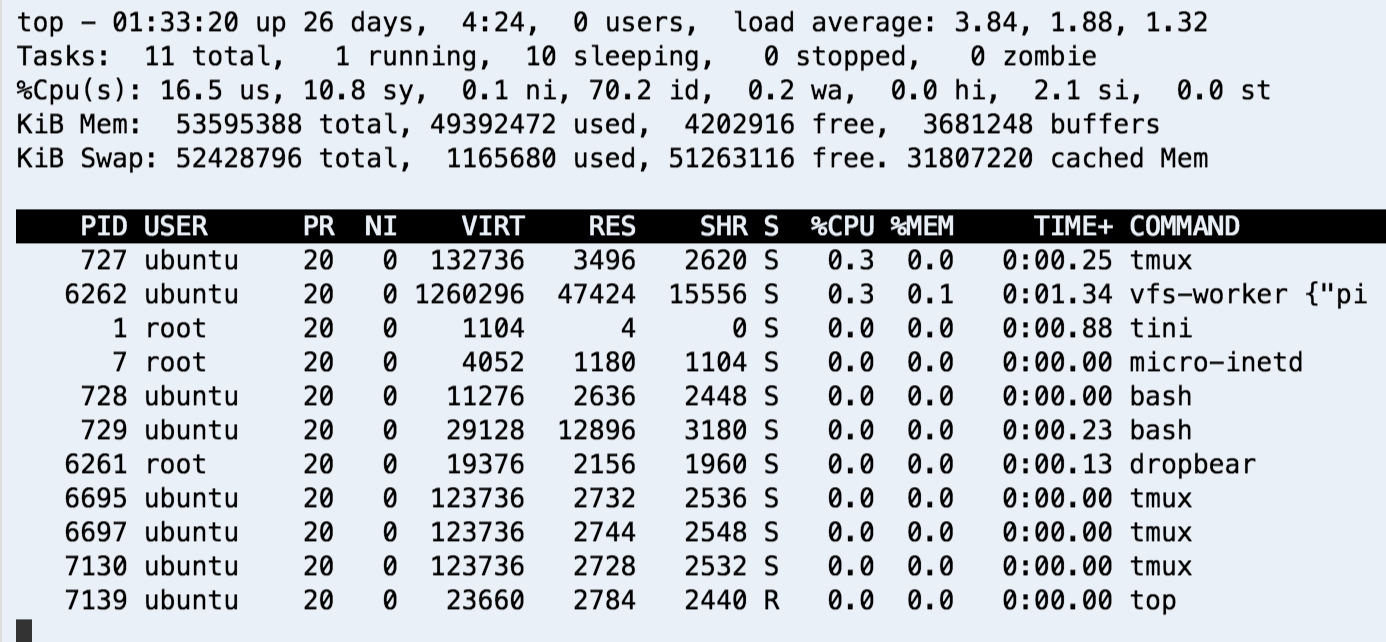
1行目 top
| 項目 | 内容 |
|---|---|
| 項目名なし(基本情報) | 現在時刻 稼働時間 ログインユーザー数 |
| load average | 時間あたりの待機タスク数(1分ごと 5分ごと 15分ごと) |
uptimeというコマンドでも同じ内容が表示されます。 特に時間あたりの待機タスク数(ロードアベレージ)は重要な指標です。
2行目 Tasks
| 項目 | 内容 |
|---|---|
| total | タスク合計 |
| running | 稼働中タスク数 |
| sleeping | 待機中タスク数 |
| stopped | 停止中タスク数 |
| zombie | ゾンビタスク数 |
Linuxでは基本的にタスクとプロセスはほぼ同じ意味で使われます。
3行目 Cpu
| 項目 | 内容 |
|---|---|
| us | ユーザプロセスの使用時間 |
| sy | システムプロセスの使用時間 |
| ni | 実行優先度(nice値)を変更したユーザプロセスの使用時間 |
| id | アイドル時間 |
| wa | I/Oの終了待ち時間 |
| hi | ハードウェア割り込み要求での使用時間 |
| si | ソフトウェア割り込み要求での使用時間 |
| st | OSの仮想化を利用している時に、他の仮想CPUの計算で待たされた時間 |
4行目 Mem
| 項目 | 内容 |
|---|---|
| total | メモリーの合計容量 |
| used | 使用中容量 |
| free | 未使用の容量 |
| buffers | バッファとして利用されている容量 |
5行目 Swap
| 項目 | 内容 |
|---|---|
| total | スワップ領域の合計容量 |
| used | 使用中のスワップ領域の容量 |
| free | 未使用のスワップ領域の容量 |
| cached | キャッシュされているスワップ領域の容量 |
スワップ領域とは
使用中のメモリ容量が実メモリの容量を上回った時に使われる、 外部記憶装置の記憶領域のことです。 実メモリに比べて処理速度が遅いため、全体の処理速度の低下につながります。
6行目以下 プロセスについて
| 項目 | 内容 |
|---|---|
| PID | プロセスID |
| USER | 実行ユーザ名 |
| PR | 静的優先度 |
| NI | 相対優先度(NICE値) |
| VIRT | 仮想メモリサイズ |
| RES | 利用しているメモリ容量 |
| SHR | 利用している共有メモリ容量 |
| S | プロセスの状態 |
| %CPU | CPU使用率 |
| %MEM | 物理メモリ使用率 |
| TIME+ | プロセスの実行時間 |
| COMMAND | プロセスで実行されているコマンド |
ロードアベレージとは
ロードアベレージとは、単位時間あたりの実行待ちプロセス数です。 ロードアベレージの値がCPUのコア数より多い場合、サーバが重くなります。 コア数は以下のコマンドで確認可能です。
cat /proc/cpuinfo | grep processor
ロードアベレージが高い場合
ケースA CPU使用率が高い
CPU使用率がほぼ100%になっている場合は、 CPUが原因である可能性が高くなります。
想定される原因
特定のプロセスのCPU使用率が高くなっていることが考えられます。 そうでなければ、CPUの処理速度が不足していると考えられます。
対処方法
psコマンドでどのプロセスが原因になっているのかを調査し、 プロセスを終了させたり、nice値(プロセス実行スケジューリング の優先順位)を変更したりなどプロセス毎に対応します。 また、topコマンドを実行中に「Shift + P」を押すと CPU使用率の高い順にプロセスがソートされます。
ケースB メモリ使用量が多い
スワップが発生している場合は、 メモリ使用量が原因である可能性が高くなります。
想定される原因
特定のプロセスが極端にメモリを消費している場合、 プログラムの不具合・非効率などの可能性があります。 特定のプロセスに集中しているのでなければ、 メモリ不足の可能性が高くなります。
対処方法
プログラムに不具合があればその修正をすることになります。 メモリ不足ならばメモリの増設か処理の分散を検討することになります。
参考
メモリ不足については、メモリの仕組みを理解していないと 誤解してしまう可能性があります。 メモリの仕組みについての理解が重要です。 http://www.atmarkit.co.jp/ait/articles/0810/01/news134.html
ケースC ディスクI/Oの終了待ち時間が長い
ディスクI/Oの終了待ち時間が長い場合、 I/O頻度が原因である可能性が高くなります。
想定される原因
アプリケーションの都合上避けられない場合もあるが、 プログラムが非効率な可能性もあります。
対処方法
データの分散 キャッシュサーバの導入 メモリ増設でキャッシュ領域を拡大
ロードアベレージが低い場合
ケースD TCPコネクションが多い
数万のTCPコネクションが貼られている場合、 TCPコネクションが原因である可能性があります。
想定される原因
特定のサーバにTCPコネクションが集中している可能性があります。
対処方法
サーバの増設を行い負荷分散を行う必要性が考えられます。
ケースE 上記のいずれにも当てはまらない場合
他のホストに原因がある可能性が高くなります。